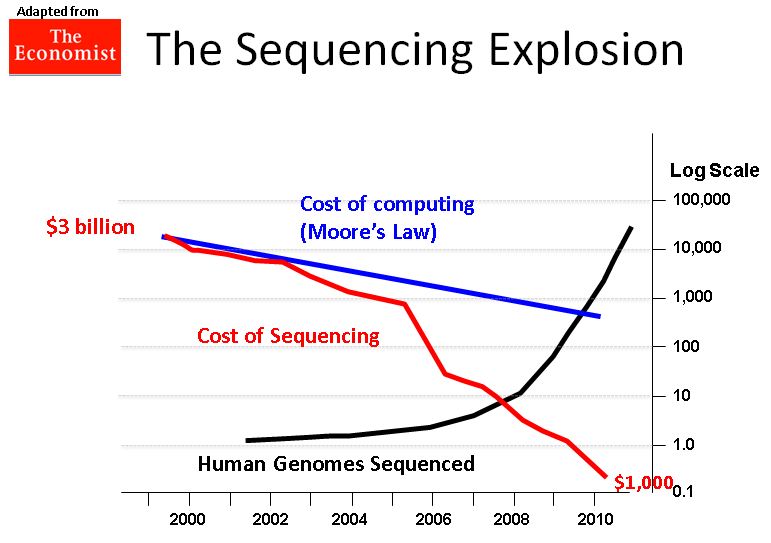
As a human society, we are in the middle of a revolution related to the understanding of living systems. We have to go back to 2001 for the first draft of the human genome and since then, several other individuals have been sequenced and their data made available, for research purpose, to the scientific community. This revolution has been possible thanks to the improvement of the throughput of sequencing techniques that allowed the investigation of whole genomes at the single nucleotide resolution at a reasonable price (Fig. 1).
1) Relationships between the cost of computing (blue line), sequencing (red line) per human genomes (black line) during the last 10 years (ref. 1).
Together with genomic, other layers of life complexity entered into the "omic" era. In fact, it is now possible to investigate multiple sources of cellular information coming from genetic, epigenetics and molecular biology in a novel field called "multiomics". This interdisciplinary discipline, together with the usage of big data analytics methods, is changing the way we are looking at biological phenomena or understand complex traits and disease.
One example of a big data application to understand and model complex biological phenomena is the genome-wide association's studies (GWAS). In this type of research, the question to address is: are there specific genetic variants (single nucleotide variation SNP) involved in a particular phenotype? Let's take for example obesity, a quantitative trait that is measurable for every individual. In such experiments, it is possible to collect the body mass index (BMI) of thousands of individuals possibly from the same population and test if a small portion of genetics variants out of the millions in the human genomes are functionally involved in its predisposition (Fig. 2).

Fig2. Manhattan plot of a GWAS study for body max index (BMI). The x-axis is showing the chromosomes and in the y-axis, the -log10 p-value for each SNP represented as the colored dot (figure from Locke et al Nature 2015).
These type of studies are a typical example of big data analytics in genomics. For the purpose of these studies (ref. 2), scientists have to handle the genomic information (as millions of SNPs) of thousands of individuals and perform statistical tests to find a possible relationship between SNPs and the measured trait (in our case obesity). But this is not all. Let's try, for example, to ask: are there any genes affected in their regulation for individuals with obesity? Together with the sequenced genome, it is possible to sequence the transcriptome, that is the snapshot of which gene is expressed, in a particular condition in an individual. This time the test to be performed will be between SNPs and the expressed genes. And we can continue for several other molecular phenotypes such as histones modifications, DNA modifications and so on.
These are just a few examples of big data analytics applications in the genomic field. Together with novel cloud computing infrastructures and standardized pipeline for the reproducibility of the results these approaches could be a novel way to discover markers for the treatment of diseases such as obesity and understanding the underlying biology behind. Once the data are collected and available for a given experimental design, the speed and the time investment in these types of research are minimal. This can be a way to handle the "failing fast" requirement during the drug discovery screening development (ref. 3).
A new biotech start-up named 23andMe is already involved in these types of services and big pharma company such as GlaxoSmithKline are getting closer to this novel reality for the treatment of human diseases (ref. 4). These new strategies of R&D operation involving big data analytics offered from company such as IBM Watson (ref. 5), high-throughput sequencing and standardized pipeline for the reproducibility of the results as offered by lifebit (ref. 6) might be a novel way of operating during the screening process of candidate chemical compounds for precision medicine.
 | ||||||||||||
| . |
Together with genomic, other layers of life complexity entered into the "omic" era. In fact, it is now possible to investigate multiple sources of cellular information coming from genetic, epigenetics and molecular biology in a novel field called "multiomics". This interdisciplinary discipline, together with the usage of big data analytics methods, is changing the way we are looking at biological phenomena or understand complex traits and disease.
One example of a big data application to understand and model complex biological phenomena is the genome-wide association's studies (GWAS). In this type of research, the question to address is: are there specific genetic variants (single nucleotide variation SNP) involved in a particular phenotype? Let's take for example obesity, a quantitative trait that is measurable for every individual. In such experiments, it is possible to collect the body mass index (BMI) of thousands of individuals possibly from the same population and test if a small portion of genetics variants out of the millions in the human genomes are functionally involved in its predisposition (Fig. 2).

Fig2. Manhattan plot of a GWAS study for body max index (BMI). The x-axis is showing the chromosomes and in the y-axis, the -log10 p-value for each SNP represented as the colored dot (figure from Locke et al Nature 2015).
These type of studies are a typical example of big data analytics in genomics. For the purpose of these studies (ref. 2), scientists have to handle the genomic information (as millions of SNPs) of thousands of individuals and perform statistical tests to find a possible relationship between SNPs and the measured trait (in our case obesity). But this is not all. Let's try, for example, to ask: are there any genes affected in their regulation for individuals with obesity? Together with the sequenced genome, it is possible to sequence the transcriptome, that is the snapshot of which gene is expressed, in a particular condition in an individual. This time the test to be performed will be between SNPs and the expressed genes. And we can continue for several other molecular phenotypes such as histones modifications, DNA modifications and so on.
These are just a few examples of big data analytics applications in the genomic field. Together with novel cloud computing infrastructures and standardized pipeline for the reproducibility of the results these approaches could be a novel way to discover markers for the treatment of diseases such as obesity and understanding the underlying biology behind. Once the data are collected and available for a given experimental design, the speed and the time investment in these types of research are minimal. This can be a way to handle the "failing fast" requirement during the drug discovery screening development (ref. 3).
A new biotech start-up named 23andMe is already involved in these types of services and big pharma company such as GlaxoSmithKline are getting closer to this novel reality for the treatment of human diseases (ref. 4). These new strategies of R&D operation involving big data analytics offered from company such as IBM Watson (ref. 5), high-throughput sequencing and standardized pipeline for the reproducibility of the results as offered by lifebit (ref. 6) might be a novel way of operating during the screening process of candidate chemical compounds for precision medicine.
References
- https://chrissemsarian.wordpress.com/category/genome/
- Locke, Adam E., et al. "Genetic studies of body mass index yield new insights for obesity biology." Nature 518.7538 (2015): 197.
- https://www.toptal.com/insights/innovation/pharmaceutical-r-and-d-big-data
- https://www.scientificamerican.com/article/23andme-is-sharing-genetic-data-with-drug-giant/
- https://www.ibm.com/watson/de-de/health/life-sciences/
- https://lifebit.ai/
Nessun commento:
Posta un commento